일반 라이센스는 SW에 대한 공유와 수정의 자유를 제한하려는 목적을 가진 반면 GPL은 공유와 수정의 자유를 보장하기 위한 규정
상업적 사용이 가능하다.
다만, 공개 및 상업적 사용시 무료 공개를 해야한다.
내부 사용시 (개인, 기관, 단체 내부) 무료 공개의 의무가 없다.
GPL 코드의 일부만 사용하더라도 GPL 라이센스를 갖는다.
LGPL (Lesser General Public License, GNU LGPL)
GPL 은 GPL 인 라이브러리를 사용만해도 2차 저작물에 GPL 이 적용되어, 상업적 사용은 가능하지만 소스 코드가 공개되어야하는 단점을 갖습니다.
FSF(Free Software Foundation) 는 이런 이유로 GPL 라이브러리 사용 기피 방지 및 오픈 소스의 기여를 위해 코드 자체를 수정하지 않는한 공개 조항을 강제하지 않습니다.
기본적으로는 GPL 과 동일하다.
LGPL 코드를 단순 사용 시 무료 공개의 의무가 없다. 사용했음만을 명시하면 된다.
LGPL 코드를 수정 사용 시 무료 공개를 해야한다.
BSD (Berkeley Software Distribution) License & MIT License
유닉스 계열 운영체제인 BSD 가 유닉스의 원 제작자인 AT&T의 벨 연구소에게 소송을 당하게 되고, 그 이후 소스코드 작성자 이름 표기 외에 어떠한 저작권 내용이 없는 라이센스를 만들어 배포합니다. 추가로 MIT 는 BSD 와 거의 유사하여 따로 항목을 생성하지 않았습니다.
소프트웨어계의 공공재
수정 가능, 자유로운 사용
공개의 의무가 없다.
초기 4조항 버전에서 조항이 하니씩 빠지면서 3조항, 2조항 버전이 있습니다.
4조항 - Original
광고에 원 저작권자 표기 필수
광고에 2차 저작권자 표기 불가
3조항 - BSD License 2.0
광고에 원 저작권자 표기 필수 (제거)
광고에 2차 저작권자 표기 불가
2조항 - FreeBSD License
제품에 BSD 라이센스 내용과 원, 2차 저작권자를 표기해야하는 의무
5. Apache License
BSD 라이센스는 공공재에 가까운 조항으로 2차 저작물에 대한 어떠한 특허도 요구할 수 없습니다.
Apache License 는 이 라이센스 코드를 자신이 활용하여 2차 저작물을 만들어도 그에 대해 특허를 가질 수 있습니다. 단 그렇게 하려면 해당 저작물에는 더 이상 Apache License 를 적용해선 안되겠지요.
공개의 의무가 없다.
2차 변형물의 특허출원이 가능하다.
다만, 수정 여부 및 아파치 재단 이름과 라이센스 내용을 명시해야한다.
간단한 이해를 위해서 위와같이 정리해 보았는데요. 역시나 가장 재미있는것은 각 라이센스들이 왜? 어떻게? 에 해당하는 역사겠지요. 아래 링크^1에서 약간 상세하게 풀어놓았으니 참조하시면 큰 도움이 되실겁니다.
iOS 는 어떻게 보면 웹 어플리케이션 개발과 거의 유사하다고 생각됩니다. 다만 .NET WebForm 처럼 View 와 Controller 가 강결합 되어있어서, React.js 렌더링(프론트) 로직과 View 데이터를 전달해주는 Controller 를 따로 생각할 수 없습니다. 처음 스위프트 앱을 만들때 앱도 결국 웹 페이지와 거의 유사한 모델이기 때문에 웹 어플리케이션 개발 방식 그대로 개발하려했습니다. MVC 와 MVVM 에 대한 작은 경험을 그대로 적용해보았습니다.
MVC / MVVM
기존 웹 어플리케이션을 만들때 서버에서는 Controller, Application, Service, Repository 순으로 분류하여 작업했습니다. HTML, Javascript 는 View 에, JPA 같은 데이터 레벨은 Model 에, Model 을 활용한 모든 비지니스 로직과 View 와 POST/GET 통신으로 이벤트를 주고받는 중간 레이어는 Controller 에 해당합니다. 웹 어플리케이션에서 MVC 의 Controller 는 사실상 View Model 에 해당합니다. View 를 그려주는것이 아니라 View 를 그릴 수 있는 View Model 을 전달해주고 이를 처리하는건 클라이언트 엔진위인 Single Page 니까요. 이름만 들어도 알만한 프론트엔드 프레임워크인 .js 류들이 이런 패턴을 사용합니다.
iOS - Massive Controller ? (Actually It’s ‘View’ not a Controller)
MVVM 패턴을 그대로 적용하려니 iOS 에서 에러가 발생합니다. 문제의 핵심은 View.storyboard 와 ViewController.swift 가 사실상 하나의 View 라는겁니다. 일반적으로 프론트엔드와 백엔드의 코드 베이스가 JS, Java 등으로 나뉘는것과 달리 iOS Swift 는 View 를 모두 .swift 에서 처리합니다. ViewController.swift 가 Controller 라는 이름을 갖고있지만 사실상 View 에 해당하고 View.storyboard 는 CSS/HTML 및 Router 가 포함된 개념으로 볼 수 있습니다.
스위프트는 본질적으론 MVC 패턴입니다. 다만 언어의 특성상 웹 어플리케이션의 MVC 와는 조금 구별해야하는것 처럼 보입니다. Controller 가 사실상 View 에 해당하는것이기 때문에 렌더에 해당하는 로직을 Controller 가 갖습니다. Service, Repository 모듈화를 잘한다해도 Controller 에는 View 렌더 로직뿐만 아니라, View 렌더에 필요한 데이터 조작에 대한 ‘일부’ 비지니스 로직도 포함하게 됩니다. 이 문제를 Massive Controller 라고 칭합니다.
첫 개발 - MVC
MVC 를 그대로 적용해본 제 첫 Swift 코드는 아래와 같았습니다. Bar 같은 여러 Asset 에 그려줄 데이터(Model)들을 받아와서 통계 데이터를 만들고(비지니스 로직) 그걸 View 에 주입해서 그려주었죠(View). 물론 보시는것과 같이 간단한 UIView 임에도 View 를 그리는 로직뿐만 아니라 View Model 에 대한 로직을 보실 수 있습니다.
리팩토링 - MVVM
Controller 가 커지면 무의식적으로 불안감이 발생합니다. 코드를 작성하면서 이건 정말 아닌것같은 느낌을 많이 받으며 리팩토링을 수행했습니다. 사실상 View 의 의미를 갖는 Controller 아래에 진정한 의미의(…) Controller인 View Model 을 두는 것입니다. 모양, 색깔, 크기에 해당하는건 ViewController 에 두고 이에 필요한 ViewModel 은 ViewModelController 가 제공하는것입니다. 아래 예를 보면 ViewController 에서 ViewModel 인 mockBudgets 만을 잘 사용하고 있습니다. View(Controller)와 ViewModel(Controller) 바인딩 시 Rx 를 사용한다고 하는데 아직 이것까진 적용해보지 못했습니다.
최근 - VIPER
그러다 개인 프로젝트이기에 시간 날때마다 작업을 하니 제가 짠 코드도 몇일 몇주가 지나서 보면 너무 새로운 겁니다. 매번 개발을 진행할때, 더 진척이 생길때마다 코드를 다시 읽고 이해하는 시간이 길어졌고, 이건 코드들이 각 구체적이고 명확한 역할을 가지지도 않는다는걸로 이해됐습니다. 물론 Service, Repository 레벨의 코드들은 정리가 잘되어있어서 문제가 없었지만 View 는 아무리 적응하려해도 힘들더군요. 심지어 저는 Swift 를 처음 공부하면서 첫 어플리케이션을 만들고 있는것이니까요.
VIPER
VIPER 는 사실 View Model 의 이중화라고 보면 됩니다. 기존 비지니스 로직을 View 와 연관된 비지니스 로직, Model 데이터 레벨에 가까운 비지니스 로직 및 로깅, 네트워크 인스턴스 관리 이렇게 둘로 세분화한것으로 이해하면 쉽습니다. 전자를 Presentator 후자를 Interactor 라고 부릅니다. 그렇게 3개에서 4개의 컴포넌트가 되었습니다. 거기에 ViewController 간 화면 전환과 같은 segue 처리를 맡는 Router 가 추가되어 총 5개가 됩니다.
제 기존 코드에서 Model 은 이미 잘 정리되어있었기 때문에 이 부분은 Entity 와 Interactor 로 이미 분리되어 있었습니다. ViewModel 에도 최대한 Model 에 대한 로직은 넣지 않았으니까요. 기존 ViewController 에 몰려있던 View 에 대한 관련 비지니스 로직들을 Presentator 로 이관을 해보니 기존 View 에 View Model 로직들이 너무 많았었구나 싶었습니다. 또한 화면 전환(segue) 처리도 기존 ViewController 가 갖고있었는데 사실 이건 메타적으로 생각해보면 ViewController 간 이동을 조율하는것이므로 상위 레벨의 컴포넌트가 관리하는게 맞았습니다. segue 이동에 대해 매 ViewController 마다 중복해 갖는 보일러플레이트 코드들을 어떻게 중앙처리할까 했더니 VIPER 의 Router 를 사용하면 되는것이었습니다.
이렇게 적용을 해보았는데 컴포넌트가 5개이다 보니 기반 코드가 너무 많습니다. 귀찮았지만 앞으로의 생산성을 위해 적용해봤는데요. 효과는 아직 모르겠습니다. ReSwift(Redux on Swift) 개념도 있는듯한데 React.js 를 짧게 사용해보면서 컴포넌트들이 해봐야 고작 1, 2 레이어여서 굳이 Redux 를 적용할 필요가 없었기 때문에 배워보지 못했습니다. 이건 추후에 적용해보는걸로 해야겠습니다. 아무래도 새로운 아키텍쳐 패턴이나 요즘 핫하다는걸 적용해보면 좋겠지만 아무리 개인 개발이라도 빨리 배포를 하는게 더 중요하겠지요.
처음 Kotlin 를 사용하던 중에 비동기 처리를 위해 Coroutine 개념을 마주했었습니다. 동기란 요청을 보낸 후 요청에 대한 반환값을 얻기 이전까지 대기하는걸 의미하고, 비동기는 그 대기시간동안 다른 일을 수행하여 효율성을 높히는걸 의미합니다.
동기와 비동기는 ‘대기’가 필요한 작업들이 빈번한 프로그래밍에 등장하는 개념이고 이를 ‘blocking’으로 명명하여 예로는 OS 시간에 배웠던 I/O 나 Network Request/Response 처리가 있습니다. 과거에는 앞서 말한 예를 처리할때에만 비동기를 사용했던것으로 기억하는데요. 현재에는 어떤 작업이든지 잘게 쪼개어 비동기로 하는 것으로 보입니다. 이런 분위기를 이끌어 온것은 사용이 간편해짐을 들 수 있는데 여기서 설명할 Coroutine 개념도 Thread 보다 비동기 사용이 쉽도록 만들어주었기 때문아닐까 생각이 듭니다.
Process & Thread
Process: Program 이 메모리에 적재되어 실행되는 인스턴스 Thread: Process 내 실행되는 여러 흐름의 단위
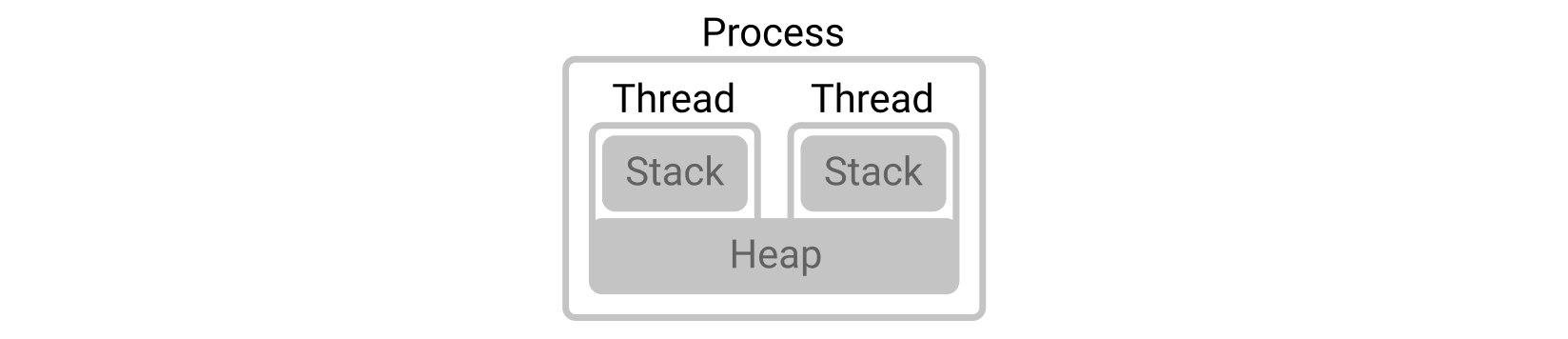
먼저 Thread 는 Process 보다 작은 단위의 실행 인스턴스로만 알고 있는데, 메모리 영역도 조금 다릅니다.
Process 는 독립된 메모리 영역**(Heap)을 할당받고 각 **Thread도 독립된 메모리 영역**(Stack)**을 할당받습니다. Thread 는 본질적으로 Process 내에 속해있기 때문에 Head 메모리 영역은 해당 Process 에 속한 모든 Thread 들이 공유할 수 있습니다.
Program 에 대한 Process 가 생성되면 Heap 영역과 하나의 Thread 와 하나의 Stack 영역을 갖게되고, Thread 가 추가될때마다 그 수만큼의 Stack 이 추가됩니다. Thread 가 100 개라면 전체 메모리에 100 개의 Stask 이 생성되는 것입니다.
Concurrency & Parallelism
Concurrency 동시성
Interleaving, 시분할: 다수의 Task 가 있는데, 각 Task 들을 평등하게 조금씩 나누어 실행하는것
총 실행시간은 Context Switching 에 대한 비용을 제외하곤 각 Task 수행시간을 합친것과 동일합니다. 예를 들어 3 개의 Task 각각이 10분씩 걸린다고 했을때, 총 30분이 소요되는것입니다.
Parallelism 병렬성
Parallelizing, 병렬수행: 다수의 Task 가 있는데, 각 Task 들이 한번에 수행되는 것
Task 수 만큼 자원이 필요하며, Context Switching 은 필요없습니다. 총 실행시간은 다수의 Tasks 중 가장 소요시간이 긴 Task 만큼 걸립니다. 예를 들어 3 개의 Task 각각이 10, 11, 12분씩 걸린다면, 총 12분이 소요되는것입니다.
Thread & Coroutine
Thread, Coroutine 모두 Concurrency 동시성 (Interleaving) 를 보장하기 위한 기술입니다. 여러개의 작업을 동시에 수행할 때 Thread 는 각 작업에 해당하는 메모리 영역을 할당하는데, 여러 작업을 동시에 수행해야하기 때문에 OS 레벨에서 각 작업들을 얼만큼씩 분배하여 수행해야지 효율적일지 Preempting Scheduling 을 필요로 합니다. A 작업 조금 B 작업 조금을 통해 최종적으로 A 작업과 B 작업 모두를 이뤄내는 것입니다. Coroutine 은 Lightweight Thread 라고 불립니다. 이 또한 작업을 효율적으로 분배하여 조금씩 수행하여 완수하는 Concurrency 를 목표로하지만 각 작업에 대해 Thread 를 할당하는 것이 아니라 작은 Object 만을 할당해주고 이 Object 들을 자유자재로 스위칭함으로써 Switching 비용을 최대한 줄였습니다.
Thread
Task 단위 = Thread
다수의 작업 각각에 Thread 를 할당합니다. 각 Thread 는 위에 설명했듯 자체 Stack 메모리 영역을 가지며 JVM Stack 영역을 차지합니다.
Context Switching
OS Kernel 에 의한 Context Switching 을 통해 Concurrency 를 보장합니다.
Blocking: 작업 1(Thread) 이 작업 2(Thread) 의 결과가 나오기까지 기다려야한다면 작업 1 Thread 는 Blocking 되어 그 시간동안 해당 자원을 사용하지 못합니다.
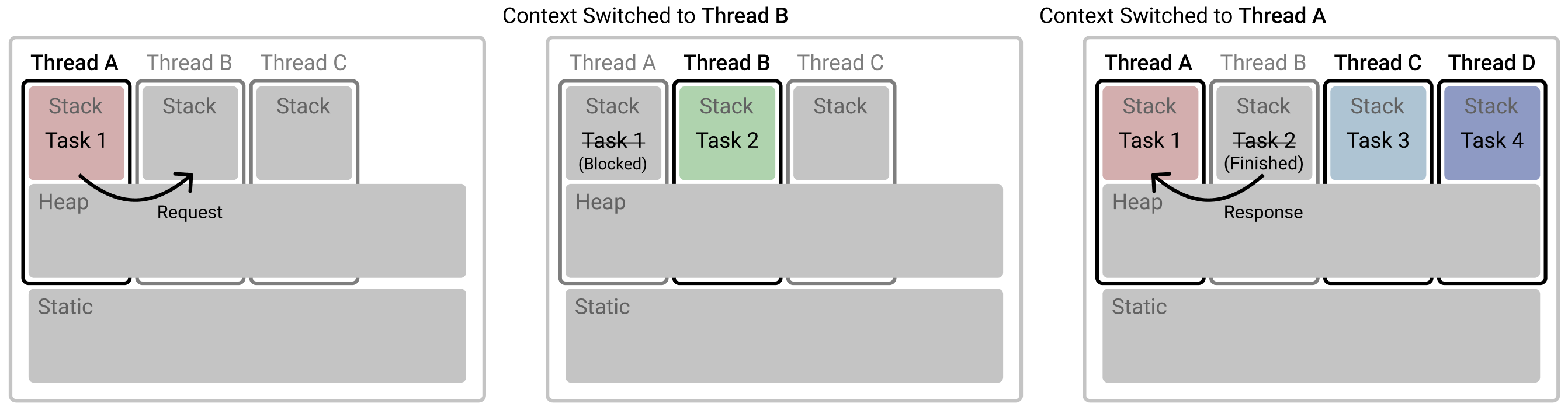
* 쉬운 설명을 위해 CPU 는 Single Core 로 가정합니다.
위 그림에서 작업들은 모두 Thread 단위인것을 알 수 있습니다. Thread A 에서 작업 1을 수행중에 작업 2가 필요할때 이를 비동기로 호출하게 됩니다. 작업 1은 진행중이던 작업을 멈추고(Blocked) 작업 2는 Thread B 에서 수행되며 이때 CPU 가 연산을 위해 바라보는 메모리 영역을 Thread A 에서 Thread B 로 전환하는 Context Switching 이 일어납니다. 작업 2가 완료되었을때 해당 결과값을 작업 1에 반환하게 되고, 동시에 수행할 작업 3과 작업 4는 각각 Thread C 와 Thread D 에 할당됩니다. 싱글 코어 CPU 는 동시 연산이 불가능하므로 이때에도 OS Kernel 의 Preempting Scheduling 에 의해 각 작업 1, 3, 4 각각을 얼만큼 수행하고 멈추고 다음 작업을 수행할지 결정하여 그에 맞게 세 작업을 돌아가며 실행함으로써 Concurrency 를 보장합니다.
Coroutine
Task 단위 = Object (Coroutine)
다수의 작업 각각에 Object 를 할당합니다. 이 Coroutine Object 는 객체를 담는 JVM Heap 에 적재됩니다.
Programmer Switching = No Context Switching
프로그래머의 코딩을 통해 Switching 시점을 마음대로 정함으로써 Concurrency 를 보장합니다.
Suspend (Non-Blocking): 작업 1(Object) 이 작업 2(Object) 의 결과가 나오기까지 기다려야한다면 작업 1 Object 는 Suspend 되지만 작업 1 을 수행하던 Thread 는 그대로 유효하기 때문에 작업 2 도 작업 1 과 동일한 Thread 에서 실행될 수 있습니다.
* 쉬운 설명을 위해 CPU 는 Single Core 로 가정합니다.
작업의 단위는 Coroutine Object 이므로 작업 1 수행중에 비동기 작업 2가 발생하더라도 작업 1을 수행하던 같은 Thread 에서 작업 2를 수행할 수 있으며, 하나의 Thread 에서 다수의 Coroutine Object 들을 수행할 수도 있습니다. 위 그림에 따라 작업 1과 작업 2의 전환에 있어 단일 Thread A 위에서 Coroutine Object 객체들만 교체함으로써 이뤄지기 때문에 OS 레벨의 Context Switching 은 필요없습니다. 한 Thread 에 다수의 Coroutine 을 수행할 수 있음과 Context Switching 이 필요없기 떄문에 Coroutine 을 Lightweight Thread 로도 부릅니다.
다만 위 그림의 Thread A 와 Thread C 의 예처럼 다수의 스레드가 동시에 수행된다면 Concurrency 보장을 위해 두 Threads 간 Context Switching 은 수행되어야합니다. 따라서 Coroutine 을 사용할때에는 No Context Switching 이라는 장점을 최대한 활용하기 위해 다수의 Thread 를 사용하는 것보다 단일 Thread 에서 여러 Coroutine Object 들을 실행하는 것이 좋습니다.
결국 Coroutine 으로 ‘작업’의 단위를 Thread 가 아닌 Object 로 축소하면서 작업의 전환 및 다수 작업 수행에 굳이 다수의 Thread 를 필요로 하지 않게됩니다.
Coroutine 은 Thread 의 대안이 아니라 기존의 Thread 를 더 잘게 쪼개어 사용하기위한 개념이다. 하나의 Thread 가 다수의 코루틴을 수행할 수 있기 때문에 더 이상 작업의 수만큼 Thread 를 양산하며 메모리를 소비할 필요가 없다.
각 스레드마다 갖는 Stack 메모리 영역을 갖지 않기때문에, 스레드 사용시 스레드 개수만큼 Stack 메모리에 따른 메모리 사용공간이 증가하지 않아도 된다.
같은 프로세스내에 ‘공유 데이터 구조’(Heap)에 대한 locking 걱정도 없다.
Thread 와 Coroutine 의 예로 보여드린 그림들을 위와 같이 축약해보았습니다. Coroutine 을 사용한다면 Task 가 바뀌어도 Thread 는 그대로 유지되는 것을 볼 수 있습니다. 그에 따라 자연스레 Context Switching 횟수도 확연히 줄어들은것을 볼 수 있습니다. Coroutine 에서 설명드린바와 같이 Task 3 과 Task 4 도 Thread C 가 아닌 Thread A 에서 수행되도록 한다면 하나의 Context Switching 도 없게 설계할 수 있습니다. 즉, Coroutine 이 수행될 Thread 도 프로그래머가 Shared Thread Pool 을 지정하여 결정한다는 의미이며, Coroutine 을 활용한 효율성은 오로지 프로그래머의 몫이라는 의미입니다.
Non Blocking Cancellable ‘Future’(Java) = Coroutine Object
Coroutine Builder 인 async { } 를 통해 정의된다.
Coroutine 에서 설명했듯이 Deferred 객체를 수행할땐 Thread 를 Blocking 하지 않고 해당 구문이 끝날때까지 awaits 하였다 끝나면 계속 이어간다.
Stackful & Stackless
Coroutine 을 조금 더 깊게 알아보았다면 Stackful 과 Stackless 이 두 종류로 나뉘는것을 볼 수 있다. 본 글의 맨 처음에서 언급했듯이 Thread 는 자체 메모리 영역인 Stack 을 갖는다. Stack 은 함수 실행 순서를 적재하고 그를 관리할 수 있게 해준다. Lightweight Thread 인 Coroutine 의 Stackful & Stackless 는 Coroutine 이 자체 Stack 을 가지는가? 갖지 않는가?**를 의미한다. **Stackful Coroutine 은 Coroutine 내부에서 다른 함수를 호출하였을때 해당 함수에서 현재 Coroutine 을 suspend 할 수 있음 (정확히는 yield 호출을 할 수 있음) 을 의미한다.Stackless Coroutine 은 함수에 대한 Stack 을 따로 갖지 않기 때문에 호출하려는 함수를 다시 한번 Coroutine 객체로 묶어서 ‘Coroutine 중첩 호출’을 해야지 이전 Coroutine 과 내부 Coroutine 을 suspend 를 통해 연결할 수 있다.
Coroutine - Stackful Functions
Coroutine 내부 함수에서 Yield(Suspending the Coroutine) 호출 가능
Generators - Stackless Functions
Coroutine 내부 함수에서 Yield(Suspending the Coroutine) 호출 불가능
예를 들면 Coroutine 내부에 있는 Arrays.forEach() 함수 안 구문에선 forEach() 함수를 코루틴 적용이 가능하게 따로 정의하지 않는한 Yield 호출이 불가능하다.
Kotlin Coroutine
buildSequence { }
순차적 Yield/Resuming
Yield 를 통해 멈춥니다.
Resume 을 통해 순차수행합니다.
1 2 3 4 5 6
fung() = buildSequence { yield(1); yield(2); } for (v in g()) { println(v) }
runBlocking { }
Main Thread 를 Blocking 한 채 { } 구문 내 작업을 새 Thread 에 할당하여 수행합니다.
runBlocking { } 내부에 다수의 async { } 들을 정의하였다면 해당 모든 async 들이 다 수행 완료, 반환되었을때 Main Thread 에 대한 Blocking 을 풉니다.
launch { }
Main Thread 를 Unblocking 한 채 { } 구문 내 작업을 수행합니다.
async { }
Main Thread 를 Unblocking 한 채 { } 구문 내 작업을 하고 반환값이 존재합니다.
async { } 는 launch { } 와 같은 동작을 하지만 반환값이 존재하는 Deferred 입니다. 즉, launch 는 끝까지 실행하면 끝나는거고 async 는 끝까지 실행하고 반환값을 가진 객체를 반환한다.
Deferred, which has an await() function that returns the result of the coroutine.
‘함수’를 1. 변수에 2. 파라미터에 3. 반환값에 사용할 수 있으며, 4. 순수 함수 특성을 갖습니다.
‘함수’는 일급함수(first-class function) 입니다.
‘함수’를 변수에 대입할 수 있습니다.
‘함수’를 파라미터로 넘길 수 있습니다.
‘함수’를 반환할 수 있습니다
‘함수’는 순수 함수 특성을 갖습니다.
참조 투명성 (No Side-Effects): 외부 상태나 변수, 환경의 영향을 받지 않고, 같은 파라미터로 함수를 호출하면 매 항상 같은 결과를 반환합니다.
함수 포인터
함수는 값이 아닌 참조인 만큼 함수를 일급함수로 사용하기 위해서는 함수 포인터를 이용해야 합니다.
함수 포인터를 통해 함수를 변수로 사용할 수 있습니다.
함수를 파라미터로 넘기고 싶다면 함수 포인터를 전달하면 가능합니다.
함수를 반환하고 싶으면 반환하려는 함수에 대한 포인터를 반환하면 가능합니다.
1
voidqsort(void* base, size_t n, size_t size, int (*compare)(constvoid*,constvoid*));
위 C 언어 예를 보면 퀵소트 알고리즘의 마지막 파라미터로 compare 함수 포인터를 넘겨주는걸 볼 수 있습니다. 다만 C 언어에서의 함수는 런타임에 정의된 함수가 아니라 미리 컴파일된 함수는 이유로 일급함수(first-class function)가 아닌 이급함수(second-class function)로 부르자는 의견^3도 있는듯 합니다.
람다 (익명함수)
람다는 컴퓨터과학 및 수리논리학에 사용되는 개념으로 현 프로그래밍 함수의 원형에 해당하는 개념입니다.
입력값을 받고 함수 외부에 정의된 자유변수를 활용하여 결과를 반환하는 함수 추상표현법 입니다.
함수를 정의만 할 뿐 수행하지 않는다는 점이 프로그래밍 내에서 함수를 정의를 먼저하는 것^8과 같습니다. 수리논리 개념이자 함수의 원형인만큼 람다는 함수명이 존재하지 않습니다. 이런 이유로 람다를 프로그래밍에서는 익명함수로 부르기도 합니다. 개념이라는 것은 알겠는데 그럼 람다는 언제 왜 사용되는것일까요?
람다는 변수, 파라미터, 반환값에 함수 포인터를 넘겨준다는 것은 일반 함수 사용과 동일하지만, 함수 정의 시점이 다르기 때문에
함수 이름이 필요없으며
함수의 유효범위가 일회성이라는 장점이 있습니다.
일반 함수는 정의 시 정의 구역 내 전역으로 존재합니다. (어려운 말로 전역 네임스페이스에 소속되는 정적인 구현체^1)
람다는 정의 시 정의 블럭 내 일회성으로 존재합니다.
람다를 통해 함수를 일급함수로 사용 시 미리 정의할 필요없이 inline 으로 함수를 정의하여 바로 사용이 가능해졌습니다.
함수객체
객체지향 프로그래밍에서는 함수가 단일 함수로는 존재할 수 없으며 꼭 클래스안에 속해야하는 한계가 있습니다. 함수를 람다로 사용하고싶다면 함수객체를 만들어 객체레벨로 사용해야합니다. 객체지향 프로그래밍에서 람다는 겉으로 보기에는 단일 함수로 존재하는것 같지만, 실제론 이름없는 객체가 단일 함수를 감싸고 있는 ‘함수객체’의 Syntactic Sugar 라고 보시면됩니다.
람다는 익명함수를 뜻합니다. 함수를 변수, 파라미터, 반환값에 일회성으로 바로 사용하고싶을때 쓰입니다.
클로저는 함수가 정의될 때의 환경(상태)**을 갖는 **함수를 뜻합니다.^5 여기서 환경은 클로저가 정의되는 범위(Scope)에 있는 지역변수을 의미합니다.
일반적으로 클로저는 함수 A 내부에서 함수(클로저) C 를 정의하는 방식으로 많이 사용합니다. 함수 A 내에 클로저 C 가 정의된다면 C 는 A 의 변수들을 파라미터로 넘기지 않았음에도 자연적으로 참조하여 사용할 수 있습니다. 이것이 **환경(상태)**입니다.
함수 A 의 변수 와 클로저 C 의 관계를 클래스 A 내 필드와 메서드 C의 관계로 생각하시면 이해가 쉽습니다.
클로저를 함수를 객체처럼 사용하기 위한 방법으로 본다면, 클로저를 사용하는 이유는 객체를 사용하는 이유와 비슷합니다.
클로저 C 가 참조하는 외부 변수를 상태처럼 계속 갖기 때문에 반복 호출하더라도 해당 상태를 계속 활용할 수 있습니다.
외부 변수는 함수 A 범위 내에만 정의되었기 때문에 외부 접근이 불가능합니다.
1 2 3 4 5 6 7
funcquery(dbName: String) -> (String) -> (Person) { let instance: DBInstance=DBConfig.getInstance(dbName) // * 클로저 내부 { } 에서 클로저가 정의된 함수 내 존재하는 instance 변수를 사용하였습니다. return { (tableName: String) -> (Person) in return instance.getTable(tableName).getFirst() } }
Swift 클로저
위에서 살펴보았듯 클로저의 정의가 익명함수는 아니지만, Swift 에서는 클로저가 이름 없이 사용되기 때문에 익명함수이기도 합니다. Swift 의 클로저는 ‘파라미터’와 ‘반환에 해당하는 구문’을 in 으로 구별합니다.
Swift 의 클로저는 아래와 같이 원하는 만큼 축약할 수 있습니다.
기본형: 파라미터 타입, 반환 타입을 명시하고 in 이후 함수 구문을 작성합니다.
1
{ (parameters) -> (return_type) inreturn/* statements using parameters */ }
축약형: 반환 타입을 암시적으로 결정합니다
1
{ parameters inreturn/* statesments using parameters */ }
축약성애자: 반환 타입뿐만 아니라 반환 식의 return 도 없앴습니다.
1
{ parameters in/* statesments using parameters */ }
변태: 파라미터 타입을 암시적으로 결정합니다. 사용은 파라미터 순으로 $0, $1 로 사용합니다.
1
{ /* statesments using parameters with $0, $1 ... */ }
Trailing Closure: 클로저가 마지막 파라미터로 사용된다면 파라미터에 넣지않고 함수 뒤 클로저 { } 로 바로 명시합니다.
1 2
var sorted = sort(names, { $0<$1 }) var sorted = sort(names) { $0<$1 }
고차함수
**’고차함수’**는 일급함수 세 조건 중 두번째 혹은 세번째에 해당하는 함수를 뜻합니다.
‘함수’를 변수에 대입할 수 있습니다.
‘함수’를 파라미터로 받거나
‘함수’를 반환하는 함수
‘고차함수’**는 **’함수’를 파라미터로 혹은 반환값으로 사용하는 것을 의미합니다.
함수를 사용하는 함수다보니 **메타적 ‘함수’**라는 의미에서 한 차원 높은 함수, 고차함수라고 명명합니다.
사담으로 Kotlin 의 확장함수도 수신객체타입(클래스)에 대한 함수에 수신객체를 파라미터로 넘기는 형태로 사용됩니다.
Functor
Functor 는 데이터 구조입니다. Functor 개념에 앞서 함수에 대해서 짧게 살펴보겠습니다.
함수 = Mapping
함수는 Input A 를 넣으면 Output B 라는 결과가 나오는 것입니다. 달리보자면 함수는 Input A -> Output B, 이 둘에 대한 매핑입니다.
데이터 구조 Mapping
어떤 데이터 구조 전체에 대해 매핑을 적용한다면, 데이터 구조 내 원소 각각에 대해 매핑을 적용해야합니다. 예를 들어 데이터 구조가 리스트라면 0, 1 .. 이터레이팅을 통해
Pull: 각 원소를 꺼내어
Mapping: 매핑을 적용한 후
Push: 결과 원소를 반환하려는 데이터 구조에 넣습니다.
각 원소에 대한 매핑 함수를 적용할 수 있음을 Mappable 로 정의한다면, 예로 살펴본 리스트는 Mappable 데이터 구조라고 정의할 수 있습니다. 위 그림 예는 Int 데이터 구조에서 String 데이터 구조로 각 원소에 대해 stringify 한 Functor 의 예입니다.
Functor 정의
Functor 는 Mappable (Mapping 함수를 갖는) 데이터 구조^9입니다. 각 원소에 대한 매핑 함수를 적용할 수 있는 데이터 구조라면 Functor 로 부를 수 있습니다.
‘단위 원소’들로 구성된 데이터 구조
각 ‘단위 원소’에서 ‘단위 윈소’로의 Mapping 함수
어떤 1. 데이터 구조든 원하는 연산을 적용하고싶다면 데이터 구조안의 단위 원소가 어떤 타입(T)이고, 2. 단위 원소(T)에 대한 Mapping만 정의하면 됩니다. 1.을 클래스의 프로퍼티, 2.를 클래스의 메서드로 본다면 Functor 를 Function Object, 함수객체로 부르기도 합니다.^10
Functor 는 범주론(Category Theory)**에서 **카테고리에서 동일 카테고리로 사상되는 개념에서 유래했습니다. 데이터 구조에서 동일 데이터 구조로 각 단위 원소들에 대해 Mapping하는것과 개념적으로 동일한 것을 알 수 있습니다. 이처럼 데이터 구조(카테고리)는 바뀌지 않은 채 값만 Mapping 되는 것을 범주론에서는 natural transformation^6 라고 정의합니다.
Haskell’s Functor
Functor 를 찾다보면 하스켈의 Functor 개념을 먼저 접하실텐데 하스켈의 Functor 는 typeclass 로 아래와 같이 정의하며, 데이터 구조 타입을 명시해서 원하는대로 인스턴스화 하여 사용합니다. Swift-like 문법으로 표현해보면 아래로 볼 수 있습니다.
Functor (typeclass)
Operation(T) -> (R)
S (Any Data Structure)
Functor 구현 (instantiation)
Operation(Int) -> (String) { +1 and Stringfy }
List
하스켈에서 Functor 는 데이터 구조 타입(S)**과 **원소(T)에서 원소(R)로의 Mapping 추상 함수를 가진 제네릭(S, T, R) 추상 클래스로 볼 수 있습니다. 하스켈에서 fmap() 이나 map() 함수를 정의할때 Mapping 추상 함수를 정의하고 변환하고자하는 데이터 구조를 주입하면 내부 값만 바뀐 동일한 데이터 구조가 반환됩니다.
Java 유저라면 Stream 의 map() 함수를 떠올리시면 이해가 쉽습니다.
Stream 이 Mapping 함수를 가질 수 있는, Mappable 데이터 구조에 해당하므로 Functor 라고 부를 수 있고,
그 Mapping 함수는 Stream.map() 에 람다(익명함수) 형태로 정의하여 파라미터로 넘겨주면 됩니다.
Java 의 Stream 은 정확히는 모나드입니다. 이유는 Mapping 함수가
Operation(T) -> (R): **원소(T)에서 원소(T)**로 **’매핑’**하는 것이 아니라
Operation(T) -> (S): 원소(T)에서 아예 **새 Functor(S)**로 **’반환’**한다는 것입니다.
Functor 에서는 연산 전 데이터 구조에서 단위 원소를 꺼내 ‘매핑’**을 적용 후 **결과 원소를 데이터 구조에 넣었습니다. 반면 모나드에서는 연산 전 데이터 구조에서 단위 원소를 꺼내 ‘매핑’**을 적용 후 해당 원소를 **데이터 구조에 넣어서 결과 데이터 구조를 ‘반환’**합니다. 함수 자체가 데이터 구조를 반환하기 때문에 매핑 함수 결과에 **Stream.map().map().map()… 과 같이 계속해서 Chaining 으로 연결할 수 있습니다.
왜‘원소 - 원소 매핑’**이 아닌 **’원소 - 데이터 구조 매핑’**을 하는지 아래 **모나드에서 살펴보겠습니다.
Monad
모나드가 무엇인지 한 마디로 정리하기에 앞서, 왜 모나드가 필요한지에 대해 알아보겠습니다. 프로그래밍 언어의 ‘프로그래밍 함수’와 학문에서의 ‘함수’의 차이점이 무엇인지 아시는지요?
함수
함수 실행 시 내부에 어떤 상황이 발생하더라도 최종적으로 값을 반환하는걸 보장합니다.
프로그래밍 함수
함수 실행 시 내부에 어떤 처리할 수 없는 상황이 발생하면 값을 반환하지 못한채 중간에 Exception을 발생시킵니다.
고등, 대학 수학에서 그 어떠한 함수도 f(x) 중간에 실행하다가 입력해준 값이 잘못되어있으면 중간에 Exception을 내지(…) 않았습니다. 하지만 프로그래밍 함수는 작동 중 상태가 잘못되었을 경우 Exception 을 발생시킵니다.
Exception 을 발생시키는 것을 순수함수 관점에서는 Side-Effect 로 정의하기 때문에 Exception 이 발생하는 함수를 **’비순수 함수’**로 정의합니다.^7
만약 ‘프로그래밍 함수’에서 Exception 발생시 중간에 멈추는것이 아니라 해당 ‘상태’가 발생했음을 ‘상태’값으로써 결과에 함께 반환한다면 Side-Effect 는 없어지게 됩니다. 프로그래밍 함수의 순수함수화인 셈입니다. 이렇게 ‘상태’값과 함수 본연의 ‘결과’값을 함께 반환하기 위해서는 이 둘을 묶는 데이터 구조가 필요할 것 같습니다.
Functor 의 Mapping 함수를 순수함수로 만들기위해 함수의 결과에 Exception 이 발생할 수 있는 ‘상태’ 및 ‘결과’**를 **모두 포함하는 데이터 구조를 반환해보았습니다.
Functor 의 Mapping 함수가 데이터 구조를 반환하도록 만들었지만 반환되는 데이터 구조가 한번 더 Functor 의 데이터 구조로 감싸져서 반환되는 문제가 발생했습니다.
Exception ‘상태’를 갖는 데이터 구조가
Mapping 함수를 수행한 Functor 의 데이터 구조에 한번 더 감싸진채로 반환되었습니다.
Functor 는 자신의 데이터 구조의 내부 원소에서 그에 대한 연산을 수행하고 결과 원소를 데이터 구조에 Mapping 하여 반환하기 때문입니다.
불필요하게 두 번 감싸지 않고 Exception 상태만을 포함한 데이터 구조를 반환하기 위하여 Mapping 함수의 결과를 그대로 반환하고, Mapping 함수 수행 전에 갖고있는 데이터 구조에서 값을 추출하는 Unwrap 함수를 명시합니다. 이를 flatMap 함수라고 부르며 이 flatMap 으로 얻어진 ‘데이터 구조의 내부 원소’**에 대한 **Mapping 결과인 ‘데이터 구조’를 바로 반환하도록 하는것이 모나드 패턴입니다.
Monad 정의
Monad는 Unwrap(flatMap) 함수를 포함하는 Mappable 데이터 구조입니다. Monad의 Mapping 함수는 ‘결과’와 ‘상태’ 모두를 갖는 데이터 구조를 반환합니다.
‘단위 원소’로 구성된 (1) 데이터 구조
‘단위 원소’에서 ‘Exception 상태를 포함한 (2) 데이터 구조’로의 Mapping 함수
(1) 데이터 구조에서 ‘단위 원소’을 꺼내는 Unwrap(flatMap) 함수
모나드에 대한 설명을 보면 Context 와 Content 이 둘을 가진 데이터 타입으로 설명하는 글들이 많습니다. Context 를 값이 있음/없음에 대한 ‘상태’값으로, Content 는 우리가 연산하려는 ‘값’ 내지 ‘결과’값으로 설명합니다. Monad 의 Context 가 꼭 값이 있음/없음의 상태를 가져야하는것은 아니지만 일반적으로 함수 수행 중에 Exception 이 발생할 수 있는 경우들은 값이 null 인 경우가 대부분이기 때문에 많은 설명들에서 nullable 로 설명하는것 같습니다.
Function Composition
모나드는 결과 데이터 구조가 ‘상태’를 갖는다는것 뿐만 아니라 함수의 합성이 가능하다는 성질도 갖습니다.
composition with associative: 두 Mapping 함수 f(x), g(x) 가 있다면 두 함수를 합성시 f(g(x)) = (f.g)(x) 의 결과를 갖는다. 또한 associative 성질에 의해 f(g(x)) = (f.g)(x) = (g.f)(x) = g(f(x)) 도 만족한다.
이렇게 함수형 프로그래밍의 클로저, 고차함수, 커링, Functor, 모나드 총 5개의 개념을 다뤄보았습니다. 질문이나 논의할 사항이 있으면 댓글이나 개인적으로 알려주시면 감사하겠습니다. 특히 이번 글은 시니어 개발자분의 도움으로 틀린 내용들을 가다듬고 다시 보완할 수 있었습니다. 다음 글에서는 Swift 의 클로저가 외부 변수를 참조하면서 생기는 참조 순환 문제와 그걸 해결하기 위한 기법들을 설명하겠습니다.
프로그래밍 언어에서 Java 를 예로 들자면 public, private, protected 으로 필드, 함수, 클래스의 접근 범위를 제어할 수 있습니다. final, open, override, abstract 과 같이 상속 관련 키워드들도 ‘접근 제어자’의 범주에 함께 포함됩니다. (접근 제어자를 가시성 변경자 (Visibility Modifier)로 부르기도 합니다.)
취약 기반 클래스 (Fragile Base Class)
취약 기반 클래스 문제^1**는 **상속에 의해 발생하는 문제로 기반 클래스와 그를 상속하는 하위 클래스가 있다고 가정하였을 때 기반 클래스의 변경이 발생하면 하위 클래스가 깨지는 문제를 의미합니다. 기반 클래스를 하위 클래스에서 상속할 시 어떤 메소드를 어떻게 오버라이드할 지에 대한 규칙을 명시하지 않는다면 하위 클래스에서 의도와 다른 방식으로 메소드 오버라이드를 할 수 있습니다. 또한 기반 클래스의 메소드 목적이 변경되었을 때 하위 클래스의 오버라이드 메소드는 기존 의도와 예기치 못한 채 달라지게 되기 때문에 기반 클래스의 변경은 그를 상속하는 모든 하위 클래스에 영향을 줍니다. 이를 기반 클래스가 취약하다는 의미로 취약 기반 클래스라고 부릅니다.
초기 객체지향 프로그래밍 언어에 해당하는 Java, C#, C++ 의 경우에는 객체지향의 특징인 상속이 용이하도록, 접근 제어자를 따로 명시하지 않는다면 모든 기본 클래스는 상속이 가능합니다. 하지만 취약 기반 클래스 문제를 방지하기 위하여 ‘Effective Java’ 저서에서도 “상속을 위한 설계와 문서를 갖추거나, 그럴 수 없다면 상속을 금지하라”로 언급되듯 모든 기본 클래스는 상속하지 말 것을 소프트웨어 아키텍쳐 및 디자인 패턴에서 권장하고 있습니다.
초기 객체지향 프로그래밍을 사용하면서 발견된 한계와 문제들은 언어를 꾸준히 업데이트하면서 보완되기도 하지만, 새로 나오는 언어들은 이러한 좋은 패턴들을 자신들의 특징으로 가져가기도 합니다. 현대 객체지향 프로그래밍 언어인 Kotlin 과 Swift 가 그 중 하나에 속합니다. 우스갯소리로 이런 언어들을 짬뽕이라고 얘기하기도 하지만 그만큼 패턴들을 문법으로서 강제하는 장점을 갖습니다.
Swift, Kotlin - final class
Java 는 취약 기반 클래스 문제를 갖는 초기 프로그래밍 언어로써 기본적으로 모든 기본 클래스는 상속이 가능합니다. Kotlin 과 Swift 는 위 문제 해결을 위하여 기본적으로 **모든 기본 클래스는 상속이 불가능(final)**합니다. 따라서 Swift 의 두 타입인 class 와 struct 모두 기본적으로 상속이 불가능합니다.
추가로 Java 의 변수, 클래스, 함수 모두 기본적으로 아무 접근 제어자를 명시하지 않으면 package-private 로 선언되지만 Kotlin 과 Swift 의 경우 아무 접근 제어자를 명시하지 않으면 public 으로 선언되어 어디서든지 사용할 수 있으며, public 은 기본적으로 final로 상속이 불가능합니다.
Kotlin, Swift 모두 상속을 하기 위해서는 클래스, 함수, 변수 모두에 open 키워드를 추가해야합니다. 함수와 변수에 open 키워드를 사용하여 클래스 전체 레벨이 아닌 함수, 변수 레벨에서 ‘상속 가능한 것’과 ‘상속 불가능한 것’들을 쉽게 관리할 수 있다는 장점이 있습니다.
살펴본 바와 같이 Java 와 Kotlin, Swift 의 상속에 대한 처리는 완전히 반대입니다. Public 한 클래스와 함수들에게 기본적으로 상속 가능하게 하고 상속을 제한하기 위해서 private 나 protected 와 같은 접근 제한자를 사용하게 하는 Java 와 반대로 Kotlin, Swift 는 개발자들에게 기본적으로 모두 상속 불가능하게 하고 상속을 하기위해선 open 을 명시하게끔 제한함으로써 잘못 상속하는걸 방지합니다. 그래서 Swift 에서 얼핏 open 을 사용하다보면 함수, 변수 단위의 상속 여부를 결정하기 때문에 Java 에서 abstract 와 비슷하단 느낌을 받습니다.
코드를 작성하다보면 변수나 메서드를 단 하나만 생성하여 모든 곳에서 공유하여 사용할 때가 있습니다. 정적 변수와 정적 메서드에 해당하는 개념입니다. Java 와 같이 객체지향 프로그램에서는 변수, 메서드 모두 클래스 내 존재해야하는 제약사항 때문에 공유하려는 전역 변수, 메서드를 클래스에 담아서 공유해야합니다. 재미있는 점은 정적 클래스라는 개념은 없기 때문에 클래스 안의 정적 변수나 메서드는 따로 객체 초기화 할 필요없이 바로 접근이 가능함과 동시에 원한다면 이 클래스를 객체로 초기화해서도 사용가능하다는 것입니다. 객체 초기화 없이 해당 클래스의 정적 변수와 정적 메서드를 사용한다니 이게 어떻게 가능한걸까요?
Java, JVM 메모리
Java 는 JVM 위에서 프로그램을 동작시키는데요. JVM 의 M, Machine 이 뜻하는대로 작은 OS 라고 보시면 됩니다. JVM 에서 돌리는 모든 프로그램의 자원을 JVM 이 관리합니다. 이런 이유로 Java 에 대한 이해는 JVM 메모리 관리에 대한 이해와 1:1의 관계에 놓여있습니다. 싱글턴 패턴을 배우기에 앞서 정적 변수, 메서드를 이해하기 위해 클래스, 변수, 메서드가 메모리에 어떤 JVM 메모리 영역에 할당이 되고 어떻게 정리가 되는지 간단하게 살펴보겠습니다. JVM 메모리 영역은 다음 세 영역으로 나뉩니다.
변하지 않는 값을 담는 Static 영역 (이를 칭하는 용어는 아래 총 3가지가 있습니다)
변하지 않는 값을 담는다는 의미에서 Static 영역이라 부르기도 하고
객체화 되기 전 Class 그 자체를 담는다는 의미에서 Class 영역이라 부르기도 하고 (Class Loading)
객체화 되기 전 Class 의 함수를 담는다는 의미에서 Method 영역이라 부르기도 합니다.
변하는 값을 담는 Heap 영역과 Stack 영역으로 나뉩니다.
Stack 영역: 함수 내 ‘파라미터’나 ‘로컬변수’와 같이 그 함수 블록 내에만 생존하는 변수들을 저장
Heap 영역: 객체들을 저장
객체 생성의 가장 근간이 되는 Class 는 바이트코드 형태로 Static 영역에 적재됩니다. 그 Class 를 객체화할때마다 그 객체와 객체의 변수, 메서드는 위 클래스 바이트코드를 참조하여 생성된 뒤에 Heap 영역에 적재됩니다. 정적 변수, 메서드는 객체없이 Class 에 존재하는것이므로 Static 영역에 저장되겠군요. Static 영역에 Class 적재 및 객체 생성을 담당하는 것을 Classloader(클래스로더)**라고 부르며 이 로더는 커스텀하게 바꾸지 않았다면 일반적으로 JVM 위에 하나만 존재합니다. 만약 두 개의 클래스로더가 있다면 같은 정적 변수라 할지라도 각자 다른 Static 영역에 적재됩니다. **정적 변수, 메서드와 일반 객체의 변수, 메서드는 적재된 영역이 다르기 때문에 서로 참조하지 못하는 특징을 갖습니다.
싱글턴 패턴
정적 변수, 메소드
정적 변수, 메서드는 ‘클래스로더’ 내 단 하나만 존재하는 **유일무이한 “클래스”**의 변수, 메서드입니다. (클래스로더는 한 프로그램에 다수 개일 수 있습니다.)
Static 영역에 생성되는 클래스 변수, 메서드입니다.
프로그램의 시작과 동시에 클래스로더 에 의해 바이트코드형태로 Static 영역 메모리에 바로 적재됩니다.
1 2 3 4 5 6 7 8
classCalculator{ // * Public: Can be initialized from outer publicCaculator(){} // * Static: sum(a, b) publicstaticsum(Integer a, Integer a){ return a + b; } }
싱글턴 변수, 메소드
싱글턴 패턴의 정의는 ‘클래스로더’ 내 단 하나만 존재하는 **유일무이한 “객체”**의 변수, 메서드입니다. (클래스로더는 한 프로그램에 다수 개일 수 있습니다.)
Heap 영역에 생성되는 객체 변수, 메서드입니다.
프로그램 실행 도중 필요한 그 시점에 객체로 Heap 영역에 적재됩니다. 그리곤 오랜기간 사용되지 않는다면 GC 됩니다. (필요한 시점에 객체 생성하는것을 Lazy Loading 이라고 합니다. 싱글턴 패턴의 존재 의의기도 합니다.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classCalculator{ // * Priavte: Cannot be initialized from outer privateCaculator(){} // * Non-Static: sum(a, b) publicsum(Integer a, Integer a){ return a + b; }
// * Singleton: Can be initialized only once using getInstance() privatestatic Calculator uniqueInstance; publicstatic Calculator getInstance(){ if (uniqueInstance == null) { uniqueInstance = new Calculator(); } return uniqueInstance; } }
차이를 아시겠나요? 하지만 유일한 클래스의 정적 변수, 메서드든 유일한 객체인 싱글턴 패턴이든 진입점이 한 곳인 만큼 다중 스레드가 한번에 진입점에 들어올 때 서로를 어떻게 독립적으로 수행할 수 있게 보장할지가 문제가 됩니다. 이를 유식한 말로는 다수의 스레드가 모두 이 클래스 내지는 객체에 접근을 하려 경쟁한다는 의미로 **Race Condition(경쟁 상태)**라고 합니다.
Race Condition
Java 에서 다중 스레드를 사용할지라도 JVM 메모리에서는 따로 스레드별로 영역들을 지정해주지 않기 때문에 프로그래머가 접근제어를 해주지 않는다면 하나의 클래스 혹은 객체를 두 스레드에서 접근할 수 있습니다. Java 의 객체, 변수, 메서드 모두 기본적으로 non-blocking 이므로 여러 스레드에서 하나의 클래스 혹은 객체 접근을 동시에 할 경우 함수, 변수를 중복 호출/사용하는 문제가 발생합니다. 이를 해결하기 위해 가장 단순하게 생각할 수 있는것은 함수 단위로 blocking 하는것입니다.
위 싱글턴 패턴의 예로 사용한 Caculator 클래스의 getInstance() 함수를 두 개의 스레드에서 동시에 진입했다고 가정합시다. 동시에 if (uniqueInstance == null) 구문에 진입했을때 어느 스레드도 그 다음 라인인 new Caculator() 를 수행하지 않았다고 가정한다면 두 스레드 모두 uniqueInstance 가 null 인것으로 판단할것입니다. 그리고 그 다음 라인에 두 스레드 각각 새 객체를 생성하게 되고, 이렇게 된다면 두 스레드는 하나의 객체 함수가 아닌 각자의 객체 함수를 보게됩니다. 단순 계산 객체라면 큰 영향은 없겠지만 만약 하나의 상태를 공유하려는 객체라면 두 스레드가 서로 다른 상태를 보고있는 끔찍한 상황이 연출됩니다.
1 2 3
Thread1: getInstance() if (uniqueInstance == null) { // 2019-03-03 00:00:01 uniqueInstance = new Calculator(); // 2019-03-03 00:00:03 - Calculator 객체 1 생성 (Thread1)
1 2 3
Thread2: getInstance() if (uniqueInstance == null) { // 2019-03-03 00:00:02 uniqueInstance = new Calculator(); // 2019-03-03 00:00:04 - Calculator 객체 2 생성 (Thread2)
함수 단위 Blocking - Synchronized
다수의 스레드가 한 함수에 접근하려 한다면, 하나의 스레드가 해당 함수를 수행하는 동안에는 기다리도록 blocking 합니다. Java 가 제공하는 synchronized 키워드를 사용하면 손쉽게 해당 함수 호출을 blocking 할 수 있습니다. 이젠 Thread 1 이 해당 함수를 호출하고 끝날때까지 Thread 2 는 해당 함수 호출을 계속 기다려야합니다. 두 스레드가 한 함수를 동시에 호출할일은 없어졌습니다.
1 2 3 4 5 6 7 8 9 10
classCalculator{ ...
publicstaticsynchronized Calculator getInstance(){ if (uniqueInstance == null) { uniqueInstance = new Calculator(); } return uniqueInstance; } }
하지만 싱글턴 함수가 위에 로직보다 더 복잡하고 수행시간이 길다면 다른 스레드들은 한 스레드가 해당 함수 호출을 완료하는 그 긴 시간동안 멈춰있어야하는 성능의 이슈가 있습니다. 이런 경우에는 함수 단위의 blocking 이 아니라 함수 내 blocking 해야하는 딱 그 변수만 집어서 blocking 하는게 좋겠지요.
변수 생성 단위 Blocking - DCL (Double Checked Locking)
우리의 원래 목적은 “변수”의 스레드간 공유인데, 굳이 함수 단위의 blocking 을 해서 변수 외 나머지 로직 수행의 시간까지 손만 빨며 성능 이슈까지 발생시킬 이유는 없습니다. 똑똑한 프로그래머들의 고민 결과 “함수”가 아닌 “변수” 단위의 Blocking 을 고안해내었고 이를 **DCL (Double Checked Locking)**이라고 명명합니다. 왜 Double Checked 일까요? 아래 코드를 보시면 객체 생성 로직 진입 전과 진입 후 생성하기전에 한번 더 null 여부를 검사하기 때문인것으로 알 수 있습니다.
함수 단위 Blocking - 함수에 synchronized 추가
1 2 3 4 5 6 7
privatestatic Calculator uniqueInstance; publicstaticsynchronized Calculator getInstance(){ if (uniqueInstance == null) { uniqueInstance = new Calculator(); } return uniqueInstance; }
변수 생성 단위 Blocking - 변수에 volatile 추가, 함수 내 해당 변수에 synchronized 추가
1 2 3 4 5 6 7 8 9 10 11
privatevolatilestatic Calculator uniqueInstance; publicstatic Calculator getInstance(){ if (uniqueInstance == null) { synchronized (Calculator.class) { if (uniqueInstance == null) { uniqueInstance = new Calculator(); } } } return uniqueInstance; }
기존 방식은 getInstance() 함수에 synchronized 가 붙어있는 반면, 변수 생성 단위 Blocking 에서는 변수에 volatile 이 추가되었고, 해당 함수 내 아까 volatile 을 추가한 변수에 대해서 synchronized 붙여준걸 알 수 있습니다. 여기서 유념히 보셔야할것은 변수를 사용하는 부분이 아닌 변수를 생성하는 부분에 synchronized 를 붙여줬음을 꼭 기억하시기 바랍니다.
DCL (Double Checked Locking) 의 의미
모든 프로그램 및 스레드는 CPU 을 통해 연산들을 수행하고, 연산을 위한 변수값들은 “메인 메모리”로부터 CPU 바로 옆 “캐시”로 가져와 사용하게 됩니다. 만약 두 스레드가 각자 다른 CPU (멀티코어 환경) 에서 하나의 싱글턴 혹은 정적 변수를 공유하여 작동한다면 어떤 일이 발생할까요?
두 스레드가 공유하는 하나의 변수는 기본적으로 “메인 메모리”에 적재되어 있습니다. 각 스레드가 각 CPU 에서 값을 변경하는 경우 1) 먼저 메인 메모리로부터 캐시로 변수값을 가져오고, 2) CPU 가 해당 캐시의 값을 변경하고, 3) 캐시에 변경된 값을 메인 메모리에 작성(동기화)하는 과정을 거칩니다. 두 스레드가 동시에 변수의 값에 접근할 경우, 첫번째 스레드가 자신이 할당된 CPU 내 캐시의 변수값을 먼저 바꿨음에도 불구하고 아직 메인 메모리에 쓰지 않아 두번째 스레드는 변경된 값을 모른채 자신의 CPU 에서 독립적으로 값 변경을 수행하는 문제가 발생합니다.
그렇다고 다수 스레드가 하나의 CPU 에서 수행된다고 하더라도 아예 문제가 없는것은 아닙니다. JIT 컴파일러에 의해 어셈블리 레벨 코드 재배열(Reorder)이 발생하여 스레드 간 참조하는 변수값이 달라질 수 있기 때문입니다.
위에서 설명한 스레드간 변수 동기화 내지는 불일치 문제를 한 스레드의 값 업데이트를 다른 스레드에서는 볼 수 없다는 의미의 가시성(Visibility) 문제라고 일컫습니다. 볼 수 있다면 Visible 하다. 라고 표현합니다.
가시성 문제를 해결하기 위해 “캐시”와 “메인 메모리” 간 읽은(READ) 값이 일치하도록 강제하는 것이 volatile 키워드 입니다. 변수에 volatile 키워드를 추가하면 해당 변수는 CPU 에서 “캐시”의 값을 읽을때 동시에 “메인 메모리”의 값을 Read 함을 보장합니다. 한 스레드에서 값을 변경한다면 바로 메인 메모리에 적용되고 다른 스레드가 값을 읽을 때 최신의 값을 읽을 수 있습니다.
하지만 두 스레드가 같은 메인 메모리 값을 가져다가 변경할 경우는 여전히 문제입니다. 값을 쓰는것은 어쩔 수 없이 blocking 을 걸어두어야합니다. 한 스레드가 작성하고있다면 다른 스레드는 기다렸다가 앞 스레드가 작성을 마치면 바로 메인 메모리로부터 값을 읽어서 그 다음 쓰기를 진행하면 됩니다. 이를 위해 값을 변경(WRITE)할때는 해당 클래스에 blocking 을 거는 synchronized 키워드를 함께 사용하면 됩니다.
변수 사용 단위 Blocking - Lazy Holder
애석하게도 변수 생성 단위의 Blocking 으로 단일 생성이 완벽히 보장되진 않았습니다. 세상에, CPU 캐시까지 고려했는데 무엇을 또 놓쳤다는걸까요? 트랜지스터 레벨이라도 봐야하는 것일까요? DCL 을 통해 변수의 단일 생성 자체는 보장되었습니다. 다만 단일 생성 바로 직후에 다른 스레드에서 해당 변수를 바로 사용하려 한다면, 아직 채 완전히 생성되지 못한 변수를 사용하게 될 수 있다는 것입니다. 단일 생성을 시작하면 해당 클래스의 new ..를 통해 생성자를 수행하게 될 것입니다. 생성자가 조금이라도 복잡하다면 온전한 객체가 만들어지기 까지는 조금의 시간이 걸릴 것입니다. 하지만 해당 객체를 접근하는 다른 스레드는 그 라인의 끝마침을 기다려주지 않습니다. 이때 미처 다 온전하게 생성되지 않은 불완전한 객체를 다른 스레드에서 가져다가 사용하게 되는것입니다. 이를 out-of-order write 문제라고 명명합니다.
해결은 해당 객체가 단순히 생성되었다 여부가 아닌 완벽히 생성되었다는걸 보장하면 됩니다. 이를 보장하는 방식은 더 똑똑한 프로그래머들에 의해 정말 다양하게 제시되었는데요. 기발한것들도 있지만 그 중에 가장 이해가 쉬운것은 아래와 같습니다.
static final 로 정의된 UNIQUE_INSTANCE는 클래스로더에 의해 프로그램 시작 시 가장 먼저 Static 영역에 바로 적재됩니다. 이를 통해 getInstance() 호출되기 이전에 UNIQUE_INSTANCE = new Calculator(); 가 무조건 존재함을 보장합니다.
사실상 위에서 배운 모든 것을 활용한 해결책에 해당합니다. 개인적으로 이 해결책이 기억에 남는 이유가 C# 에서 LazyHolder 형식을 기본적으로 제공해주기 때문에 싱글턴 패턴 사용이 아래와 같이 매우 쉽게 해결했던 기억이 있습니다.
1 2 3 4 5 6
publicsealedclassSingleton { privatestaticreadonlyLazy<Singleton> lazy = new Lazy<Singleton>(() => new Singleton()); publicstatic Singleton Instance { get { return lazy.Value; } } privateSingleton() {} }
프로그래밍을 처음 배울때 우리는 먼저 변수에 대해 배웁니다. 변하지 않는 값은 Constant 상수라고 부르며, Variable 변수의 값은 수시로 변합니다. 변수는 수시로 변할 수 있기 때문에 말 그대로 프로그램 내내 산전수전을 다 겪습니다.
상태
변수는 위에서 언급한대로 정말 다양한 상태를 갖습니다. 이러한 변수의 상태를 알기 위해서는 두 가지 방법이 있습니다.
Push 방식
자동: 변수가 자신이 상태가 바뀌었음을 우리에게 알려줍니다.
Pull 방식
수동: 우리가 변수가 상태가 바뀌었는지를 직접 알아봅니다.
자동으로 우리에게 알려주는게 가장 편해보일 수도 있겠지만 굳이 알 필요가 없는데 계속해서 자신의 상태에 대해 말해준다면 매우 귀찮겠지요. 그 상태를 계속 추적하기 위한 자원도 불필요하게 낭비될것입니다. 그럴때는 우리가 필요할때만 상태를 볼 수 있는 수동의 방법도 필요합니다. 이를 조금 고지식하게 Push 와 Pull 방식으로 이야기합니다. 변수의 상태를 하나의 ‘주제’라고 본다면 주제를 중심으로 우리에게 알려주는지(Push) 아니면 **우리가 알아보는지(Pull)**에 따라 상태를 알 수 있는 방법이 나뉘는것입니다.
옵저버 패턴
옵저버 패턴은 변수의 상태를 Push 와 Pull 중 원하는 방식을 통해 알 수 있는 패턴입니다.
일반적으로 이 패턴을 설명할때 상태를 ‘주제’라 보고 Publish-Subscribe(발행-구독) 모델로 설명하곤합니다. 여기선 패턴 이름이 옵저버 패턴인 만큼 헷갈리지 않게 구독모델이 아닌 Observer와 Observable 두 가지 용어로만 설명을 드리겠습니다. 옵저버 패턴에는 앞서 말씀드린 딱 두 종류의 인터페이스만 존재합니다. 하나는 상태를 갖고있는 옵저버블, 나머지 하나는 상태를 보려하는 옵저버입니다.
Observable
위 옵저버 패턴 그림을 보시면 옵저버블 인터페이스는 두 가지 정보를 ‘구성’(has)합니다.
상태 (State)
옵저버 리스트 (Observers)
오해를 해서는 안되는 점이 옵저버블 인터페이스는 상태 자체가 아니라 상태를 ‘갖고 있다’**는 것입니다. 상태를 갖고있다는 의미로 옵저버블, 즉 **옵저버는 이 인터페이스를 통해 상태를 ‘볼 수 있다’**는 의미인것입니다. 그리고 옵저버블은 상태를 알려주거나/알아보려는 옵저버들을 리스트(물론 다른 자료구조형도 가능합니다)로 관리하여 **Push 방식의 경우에는 상태를 누구에게 보내줄지? 그리고 Pull 방식의 경우에는 상태를 누구만 볼 수 있는지? 결정할 수 있습니다.
아기돼지 삼형제를 보면 양가죽을 쓰고 하얀색 분으로 손을 칠해 양으로 변장한 늑대가 나옵니다. 물론 너무 어설픈 나머지 막내돼지한테 비웃음을 당하지만 돼지들의 집을 들어가기 위해서는 ‘변장’이 필요했던 것이죠. 이번에 얘기할 내용은 분장과 변장에 대한 이야기입니다. 여기서 잠깐 그 차이를 알아볼까요.
분장
분장은 현재 나의 모습에서 조금 더 과장한 나의 모습으로 꾸민것입니다. 나 자신은 그대로, 어렵게 말하면 본질은 해치지 않는 선에서 그 위에 무엇인가를 추가로 꾸민것이죠.
변장
변장은 현재 나의 모습에서 완전 다른것의 모습으로 꾸민것입니다. 나 자신이 아닌 완전 다른 어떤것으로 꾸민것이죠.
이번 챕터에서 배울것은 분장에 해당하는 데코레이터 패턴과 변장에 해당하는 어댑터 패턴입니다. 마지막으론 앞서 두 패턴처럼 한 클래스를 다른 클래스로 바꾸는것이 아닌 다수의 클래스를 하나의 클래스로 단순히 묶어주는 퍼사드 패턴을 다루고 마칠 예정입니다.
어댑터 패턴 - 변장
앞서 늑대가 돼지삼형제 집으로 들어가기 위해 순한 양으로 변장했습니다. 무시무시한 발톱을 하얀 분칠을 통해 예뻐보이는 손으로 바꾸었고, 그르렁거리는 목소리를 순한 양처럼 메에 흉내내기도 해봅니다. 이를 클래스로 표현하면 이해가 매우 Sheep습니다.
늑대
1 2 3 4 5 6 7 8
classWolf{ public String Claw(){ return"Sharp Claw"; } public String Growl(){ return"Grrrrrrr"; } }
늑대가 돼지삼형제 집에 들어가기 위해 양으로 ‘변장’했군요.
1 2 3 4 5 6 7 8 9
classWolfWantsToBeSheepimplementsSheep{ public Wolf wolf; public String Hand(){ wolf.Claw().replace("Sharp Claw", "White Hand"); } public String Sound(){ wolf.Growl().replace("Grrrrrrr", "Baaaaaaa"); } }
이제 늑대는 양이 들어갈 수 있는곳이면 어디든 갈 수 있습니다. 양만 들어갈 수 있는 돼지삼형제 집에 한번 들어가보겠습니다.
어떤 클래스나 함수를 클라이언트로 본다면 클라이언트들은 특정 타켓 인터페이스에만 맞게 구현되어있습니다. 이런 제약때문에 다른 클래스를 해당 클라이언트에서 사용하고 싶을지라도, 해당 클래스가 타겟 인터페이스의 구현체가 아니라면 사용할 수 없습니다. 위의 예처럼 태어났을때부터 늑대였지만 돼지삼형제 집에 가기위해서는 순한 양이 되어야하는 상황말이죠. 일반 비지니스에서도 이와 같이 어떤 클래스를 클라이언트 목적에 맞는 클래스로 사용해야하는 갑작스런 요구사항이 발생하곤 합니다.
객체 어댑터
위 늑대와 양의 예시처럼 어댑터 패턴은 어댑터라는 타겟 인터페이스의 구현 클래스를 생성하고 그 안에 타켓 인터페이스로 변장하고자 하는 클래스를 객체로 갖습니다. 이를 어댑티라고 명명하는데요. 어댑티의 원래 함수와 프로퍼티들을 활용하여 타겟 인터페이스의 각 함수들을 구현하면 됩니다.
이걸 객체 어댑터로 부르는 이유는 어댑티를 어댑터가 객체로 갖고 있기 때문입니다. 이를 우리는 ‘구성’이라고 배웠었지요. 아래의 코드를 보면 Adapter 가 Adaptee 를 객체로 가지고 있습니다. 클래스 다이어그램이 이해를 조금 더 도와줄겁니다.
1 2 3 4 5 6
publicvoidClient(TargetInterface interface);
classAdapterimplementsTargetInterface{ private Adaptee adaptee; // ... adaptee 함수를 활용해 TargetInterface 의 함수를 구현합니다. }
1
this.Client(new Adapter(new Adaptee()));
어답티는 어답터의 도움으로 TargetInterface 만을 사용하는 클라이언트에 주입가능해졌습니다.
그럼 클래스 어댑터은 무엇일까요? Adapter 가 Adaptee 를 **객체의 형태로 ‘구성’**하지 않고 **클래스의 형태로 ‘상속’**하면 됩니다.
클래스 어댑터
클래스 어댑터는 되려 단순합니다. 아래 코드와 클래스 다이어그램을 보시면 객체 어댑터와 두 가지 차이점이 있습니다.
Adapter 가 Adaptee 를 구성(has)하지 않고 상속(extends)하고 있습니다.
Target 이 Interface 가 아니라 Class 로 존재하며, 그에 따라 구현(implements)이 아닌 상속(extends)을 하고 있습니다.
객체 어댑터
1 2 3 4
classAdapterimplementsTargetInterface{ private Adaptee adaptee; // ... adaptee 함수를 활용해 TargetInterface 의 함수를 구현합니다. }
클래스 어댑터
1 2 3
classAdapterextendsTarget, Adaptee{ // ... adaptee 함수를 활용해 Target 의 함수를 확장합니다. }
위 코드를 보고 흠칫하셨을것입니다. Java 에서는 다중 상속을 지원하지 않기때문에 extends A, B 와 같은 문법은 사용할 수 없습니다. 또한 이렇게 사용할 경우 Target 이 Interface 가 아닌 Class 이기 때문에 다른 클래스로 대체할 수 없을뿐더러 Adapter 와 Target 이 단단히 엮어버렸습니다. 이는 배운대로 유연성을 해치는 구조이기에 사용을 권하지 않습니다.
다중 어댑터
다중 어댑터는 기존에 하나의 타겟 인터페이스만 지원하는것이 아닌 다수의 타겟 인터페이스를 모두 지원하는걸 의미합니다. 하나의 어댑티 클래스를 여기 인터페이스뿐만 아니라 저 인터페이스에서도 사용하고 싶을때 TargetOneInterface, TargetTwoInterface 를 하나의 어댑터 클래스로 연결하고 두 인터페이스의 모든 것을 구현하면 됩니다. 객체 어댑터가 아니라 클래스 어댑터라면 두 개의 클래스 TargetOne, TargetTwo 를 상속(extends) 하면 됩니다.
classAdapterimplementsTargetOneInterface, TargetTwoInterface{ private Adaptee adaptee; // ... adaptee 함수를 활용해 TargetOne/TwoInterface 의 함수들을 모두 구현합니다. }
데코레이터 패턴 - 분장
데코레이터 패턴은 클래스에 추가적인 기능을 무수히 많이 추가하더라도 그 클래스는 본래 클래스의 기능을 유지하는 ‘분장’에 해당합니다. 데코레이터 패턴을 어댑터 패턴 다음에 같이 다루는 이유는 사실 원리는 어댑터-어댑티 개념과 같기 때문입니다. 어댑터가 Adaptee를 TargetInterface로 변장시켰다면, 데코레이터는 Decoratee를 Decoratee 자기 자신으로 분장시키는 꼴이 됩니다.
데코레이터 패턴은 한번만 분장하기 위해 사용되지 않습니다. 자기 자신을 재귀적으로 계속 분장할 수 있는데요. 아무리 다양한 DecoratorA, DecoratorB 를 만들어 꾸미더라도 결국에 Decoratee 클래스기 때문에 기존 클라이언트에서는 크게 신경쓰지 않고 쓰던 그대로 사용하면 됩니다.
데코레이터 패턴은 Decorater 클래스가 Decoratee 를 Decoratee 로 분장하는것입니다. Decorator 는 Decoratee 를 상속받기 때문에 그 자신도 Decoratee 가 될 수 있습니다. 따라서 Decorator 는 재귀적으로 Decoratee 에 위치할 수 있어 무한정 분장될 수 있습니다.
데코레이티: 꾸미고 싶은 객체
1 2 3
classDecoratee{ // ... }
데코레이터: 꾸며주는 객체
1 2 3 4
classDecoratorextendsDecoratee{ private Decoratee decoratee; // ... decoratee 함수를 활용해 더 개선된 decoratee 함수로 확장합니다. }
단순한 코드는 위와 같지만 아마 책으로 접하신 데코레이터 패턴 코드는 아래와 같은 구조를 갖고 있었을것입니다.
정말 단순한 데코레이팅만 원하신다면 처음에 설명해드린 형태로도 충분합니다. 그렇다 하더라도 위와 같이 추상 데코레이터와 구현 데코레이터를 나누는 걸 추천드리는 이유는 다음과 같은 이점을 갖기 때문입니다.
구현 데코레이터에서 공통으로 필요로하는 로직이나 프로퍼티(특히 데코레이티)를 두고 구현 시 활용 가능합니다.
수많은 구현 데코레이터들을 추상 데코레이터 하나로 관리할 수 있습니다.
구현보다 인터페이스를 사용하라.**던 **디자인 패턴 제 1원칙 기억하시나요? 구현이 아닌 인터페이스(혹은 추상클래스)의 이점은 원하는 구현클래스를 붙였다 떼었다 할 수 있는 유용성과 재사용성이었습니다. 예를 들어 구현 데코레이터들을 하나의 리스트나 셋으로 담아 관리하고싶을때 추상 데코레이터 타입의 리스트, 셋을 생성하여 사용할 수 있겠죠.
퍼사드 패턴 - 묶음
마지막으로 배울 패턴은 퍼사드 패턴입니다. 어댑터와 데코레이터 패턴은 각 하나의 어댑티나 데코레이티를 갖는다는 공통점이 있고, 차이점은 **어댑터는 다른 클래스로 ‘변장’**하고 **데코레이터는 같은 데코레이터(사실상 데코레이티)로 ‘분장’**한다는 것 이었습니다. 퍼사드 패턴을 이 챕터에서 다룬다는것은 이들과 공통점이 있다는 것일텐데요. 어떤것이 같을까요?
퍼사드 패턴은 어댑터, 데코레이터 패턴의 공통점을 그대로 갖습니다. 어댑티, 데코레이티와 같이 활용하기 위한 클래스를 내부에 갖고있습니다. 다만 어댑터, 데코레이터가 어댑티, 데코레이티를 하나씩만 가졌다면 퍼사드는 엄청 많은 수의 클래스를 갖습니다. 그리고 어댑터와 데코레이터의 차이점이 ‘변장’이나 ‘분장’이냐의 차이였다면 퍼사드는 그저 그 자체로 새로운 클래스가 됩니다. 어댑터 패턴도 클래스 자신이 아닌 다른 클래스로 ‘변장’한다고 했는데 그럼 퍼사드 패턴도 마찬가지가 아닐까요? 아닙니다. 퍼사드 패턴은 특정 클래스가 다른 특정 클래스로 변장하는것이 아닌 다수의 클래스가 다른 하나의 클래스로 단순히 묶이는 것입니다.
(객체) 어댑터
1 2 3 4
classAdapterimplementsTargetInterface{ private Adaptee adaptee; // ... adaptee 함수를 활용해 TargetInterface 의 함수를 구현합니다. }
퍼사드
1 2 3 4 5 6
classFacade{ private ClassA classA; private ClassB classB; private ClassC classC; // ... ClassA, B, C 를 활용한 새 함수들을 만듭니다. }
퍼사드는 뒤에 어떠한 extends, implements 도 존재하지 않습니다. 단순히 여러 클래스를 묶어주는 하나의 클래스인 셈입니다.
항상 마지막에 가면 집중력이 흐트러지곤 합니다. 중간쯤 읽다보면 세줄요약을 시급하게 찾는 자신을 발견하셨을겁니다. 그래도 꼭 한번은 다 잃고 아래 세줄요약을 읽어주시기 바랍니다. 그래야 머리속에 한번에 들어갈 수 있으니까요.
어댑터 패턴
하나의 클래스(어댑티)를 다른 하나의 클래스(타겟 인터페이스)로 **’변장’**합니다.
1 2 3 4
classAdapterimplementsTargetInterface{ private Adaptee adaptee; // ... adaptee 함수를 활용해 TargetInterface 의 함수를 구현합니다. }
데코레이터 패턴
하나의 클래스(데코레이티)를 그 하나의 클래스(데코레이티)로 **’분장’**합니다.
1 2 3 4
classDecoratorextendsDecoratee{ private Decoratee decoratee; // ... decoratee 함수를 활용해 더 개선된 decoratee 함수로 확장합니다. }
위 예제 코드는 이해를 위해 간단한 데코레이터 클래스를 작성했습니다. 본문에서 설명드린바와 같이 추상/구현 데코레이터로 사용하는걸 추천드립니다.
퍼사드 패턴
다수의 클래스를 다른 하나의 클래스로 묶습니다.
1 2 3 4 5 6
classFacade{ private ClassA classA; private ClassB classB; private ClassC classC; // ... ClassA, B, C 를 활용한 새 함수들을 만듭니다. }
개발을 하다보면 어떤 상태에 따라 다른 플로를 작성해야할 상황이 발생합니다. 단순히 예/아니오 같은 단일 상태라면 if 문을 사용하도록 배웠고, 다중 상태라면 if-else 혹은 switch 를 사용하도록 배웠습니다. 코드는 간단하게는 로직의 나열이라고 볼 수 있는데요. 우리의 실생활에서도 이처럼 다중 상태에 따라 다양한 작업을 수행하곤 합니다. 결국 모든 실생활도 if-else/switch 로 설명이 가능하다는 의미겠지요.
if-else 에 “의존한” 처리
라면 종류별 끓이기
1 2 3 4 5 6 7 8 9 10 11 12 13
classRamemMaker{ publicvoidmakeRamen(String type){ Water water = new Water(100); Ramen ramen; heat(water); if (type == "볶음") { ramen = 볶음라면; } elseif (type == "국물") { ramen = 국물라면; } water.add(ramen); } }
라면 종류를 상태로 본다면 명시해준 라면 종류 String type 따라서 다른 라면을 끓입니다. 함수 makeRamen(String type) 은 아래와 같이 두 파트로 나눠볼 수 있습니다.
상태: 1.1. 라면 종류를 고르고
처리: 라면을 끓입니다.
상태와 처리라는 두 책임이 하나의 코드에 모여있군요. 1.상태와 2.처리를 한번 떼어내볼까요.
if-else 를 “분리한” 처리
라면 끓이기
1 2 3 4 5 6 7
classRamemMaker{ publicvoidmakeRamen(String type){ Water water = new Water(100); Ramen ramen = ramenGetter.getRamen(type); heat(water); water.add(ramen); }
라면 종류별 생성을 책임지는 상태 함수는 재사용성을 갖게되었고, 상태 책임이 더 명확해 졌습니다. 여기서 함수 getRamen(String type)와 같이 상태에 따라 알맞은 클래스를 만들어서 주입해주는 개념을 팩토리라고 합니다.
팩토리는 if-else/switch 와 같이 상태에 따라 다른 클래스를 생성 및 주입해주는 개념를 의미합니다. 즉 **어떤 상태(What)**인지에 따라 **어떻게 처리(How)**할지가 다릅니다.
팩토리 메서드 패턴
상태에 따라서 처리를 하기위해 RamemMaker.getRamen 함수 내부에서 if-else 문을 이용하여 분기를 탑니다. 이를 RamemMaker 의 추상 메서드로 만든다면 볶음라면(FriedRamemMaker), 국물라면(StewRamenMaker)에 따라 각각에서 getRamen 를 알맞게 구현하면 됩니다. 기존 if-else 기반 getRamen 을 간단히 팩토리라고 한다면 구현에 따라 달라지는 getRamen 추상 함수를 팩토리 메서드라고 합니다.
라면 생성 + 라면 끓이기
1 2 3 4 5 6 7 8 9
abstractclassRamemMaker{ protectedabstract Ramem getRamen(String type); publicvoidmakeRamen(String type){ Water water = new Water(100); Ramen ramen = getRamen(type); heat(water); water.add(ramen); } }
라면 종류별(볶음) 생성 + 라면 끓이기
1 2 3 4 5 6
classFriedRamenMakerextendsRamenMaker{ @Override public Ramen getRamen(String type){ returnnew FriedRamen(); } }
팩토리 메서드 패턴은 팩토리 개념을 추상함수를 통해 원하는 구현 클래스를 반환하도록 하는것입니다.
if-else + if-else
팩토리는 단순히 한 상태에 따른 구현(결과물) 클래스를 생성합니다. 라면은 라면 종류라는 한 상태뿐만 아니라 재료라는 추가 상태로도 세분화될 수 있습니다. 두 개의 상태가 생겼군요. 이를 이차원 상태로 보면 아래와 같이 if-else 문 안에 또 하나의 if-else 문을 갖는 구조로 볼 수 있습니다.
같은 볶음라면이지만 어떤 재료를 사용했는지에 따라서도 나눌 수 있는것이죠. 일차원 상태분기는 비교적 쉬웠습니다. 이차원 상태를 고려하도록 확장하려면 아래와 같이 될텐데요.
상태: 1.1. 라면 종류를 고르고 1.2. 재료를 고르고
처리: 라면을 끓입니다.
이번에는 1.상태와 2.처리라는 두 책임뿐 아니라 **두 상태인 1.1.과 1.2.**도 나누어야겠군요.
라면 끓이기
1 2 3 4 5 6 7
classRamemMaker{ publicvoidmakeRamen(String type){ Water water = new Water(100); Ramen ramen = ramenGetter.getRamen(type); heat(water); water.add(ramen); }
라면 종류별 생성
1 2 3 4 5 6 7 8 9
IngredientFactory ingredientFactory = new MeatIngredientFactory(); public Ramen getRamen(String type){ if (type == "볶음") { returnnew FriedRamen(ingredientFactory)); } elseif (type == "국물") { returnnew StewRamen(ingredientFactory)); } } }
라면에 들어갈 재료
1 2 3 4
interfaceIngredientFactory{ public Broth getBroth(); public Flakes getFlakes(); }
라면에 들어갈 고기 재료
1 2 3 4 5 6 7 8 9 10
classMeatIngredientFactoryimplementsIngredientFactory{ // 고기 육수 public Broth getBroth(){ returnnew MeatBroth(); } // 고기 건더기 public Flakes getFlakes(){ returnnew MeatFlakes(); } }
라면 종류가 함수 내 if-else 로 분기를 탔다면, 라면에 들어갈 재료는 추상 팩토리를 통해 어떤 재료든지 넣을 수 있도록 하였습니다. 전자를 팩토리 후자를 추상 팩토리라고 합니다. 1) 어떤 종류의 라면인지는 팩토리(RamenGetter.getRamen)**에서 선택하고, **추상 팩토리(IngredientFactory)**의 구상 팩토리를 통해 **2) 특정 재료를 넣어주면 최종 라면 결과물이 나옵니다.
추상 팩토리 패턴
처음 팩토리를 배울때 “팩토리 메서드 패턴”과 “추상 팩토리 패턴” 두 패턴의 차이를 이해하는데 꽤나 힘들었습니다. 하지만 **팩토리(Factory)-결과물(Product)**의 개념을 잘 이해한다면 어렵지 않습니다.
1) 팩토리 메서드 패턴은 추상 팩토리 메서드를 각 종류에 따라 구현해서 결과물(Product)을 바로 반환(Return)**했다면, **2) 추상 팩토리 패턴은 추상 팩토리(Interface 혹은 Abstract)에 따라 결과물(Product)을 다르게 **생성(Make & Return)**한다.
1) 팩토리 메서드 패턴: 볶음/국물 결정해서 바로 반환
1 2 3 4 5 6
classFriedRamenMakerextendsRamenMaker{ ... public Ramen getRamen(String type){ returnnew FriedRamen(); } }
2) 추상 팩토리 패턴: 볶음/국물 생성을 위한 재료 추상 클래스를 정의
1 2 3 4 5 6 7 8 9 10 11
classMeatRamenMakerextendsRamenMaker{ ... IngredientFactory ingredientFactory = new MeatIngredientFactory(); public Ramen getRamen(String type){ if (type == "볶음") { returnnew FriedRamen(ingredientFactory)); } elseif (type == "국물") { returnnew StewRamen(ingredientFactory)); } } }
팩토리
상태에 따라 그에 맞는 **결과물(Product)**를 반환합니다.
팩토리 메서드 패턴
추상 팩토리 메서드를 각 상태에 따라 구현하여 **결과물(Product)**을 바로 반환합니다.
추상 팩토리 패턴
추상 팩토리(Interface 혹은 Abstract)에 따라 결과물(Product)을 다르게 **생성(Make & Return)**한다.
내게 대학교 시절에 객체지향 프로그램은 다형성과 상속뿐이었지만 책이 아닌 실제 프로그래밍으로 접한 객체지향 프로그램은 학문이 아니라 실전이었습니다. 왜 이걸 배웠고 이게 사실 어떤 의미를 갖는건지 그제서야 깨달을 수 있었습니다. 여기서는 짧게 우리가 생각했던 상속을 살펴보고 디자인 패턴으로 도약하기 위해 상속을 버리는 두 개의 원칙을 익히려고 합니다.
상속 = 객체지향 프로그램?
처음 엔터프라이즈 객체지향 프로그램을 작성한다고 가정해봅시다. 학교에서 공부한대로라면 객체지향 프로그램은 상속이라고 배웠습니다. 그래서 우리는 과감히 상위 클래스를 만들고 이를 상속하여 하위 개념에 해당하는 클래스를 활용할 것입니다. 그리고 객체지향 프로그래밍 프로젝트 #1 이라고 이름 짓겠죠. 코드는 아래 헤드퍼스트 책의 예제와 같을 것입니다.
상속을 사용하였더니 상위 Duck 클래스에 있는 모든 상위 행위들을 하위 Duck 클래스들이 모두 갖게됩니다. 어떤 하위 Duck 클래스는 의지와 상관없이 갖고싶지 않지만 무조건 모든 상위 행위를 갖고 확장해야합니다. 개발에 있어 불필요한 제약을 갖게되는 것입니다. 그럼 아래와 같이 선택적으로 행위를 가져갈 수 있도록 행위를 인터페이스로 분리해 가져보겠습니다.
드디어 상위 클래스에 속하던 행위를 인터페이스로 분리하여 하위 클래스에 원하는 행위들만 붙일 수 있게 되었습니다. 하지만 두 개의 오리가 같은 소리를 갖는다면 Quackable 오리 각각에 quack() 을 똑같이 구현해주어야 합니다. 두 개의 오리면 괜찮겠지만 100 중 70 종의 오리가 같은 소리를 낸다면 70 개의 같은 quack() 구현 코드를 작성해야합니다. 그 중 몇 개의 quack() 소리를 다른 타입으로 바꾸려해도 같은 반복작업이 생기게 됩니다. 그럼 행위 인터페이스 구현을 따로 만들어서 원하는 구현을 선택적으로 가져보면 더 좋지 않을까요?
인터페이스를 구현하는것이 아닌 구성을 통해 클래스 내부 변수로 갖게되면서 원하는 행위 인터페이스 구현을 마음껏 갖고 바꿀 수 있게 되었습니다. 이로써 인터페이스를 대학교때 배웠듯이 클래스의 템플릿이다.라는 이해에서 조금 더 나아가 클래스가 갖는 행위나 특성을 담을 수 있는 하나의 ‘변수’**로 생각할 수 있으면 좋을것 같습니다. 이것이 우리가 **다형성을 배운 이유이기도 합니다.
디자인 패턴의 제 1, 2 원칙
위에서 배운 내용은 사실 아래 두 원칙에 해당합니다. 복습 겸 한번 더 복기하고 다음 챕터로 넘어가도록 하겠습니다.
구현보다 인터페이스에 맞춰서 코딩한다.
구현은 언제나 바뀔 수 있다. 인터페이스를 통해 유연하게 구현하자
fly(), quack() 같은 행위를 클래스 내부에서 구현하지 않고 인터페이스로 대체함으로써 필요한 것과 필요하지 않은 것들을 분리할 수 있습니다.
인터페이스는 ‘상속’보다는 ‘구성’으로 사용하자
인터페이스를 ‘상속’이 아닌 ‘구성’ 시 원하는 구현을 붙였다 떼었다 할 수 있다.
인터페이스를 ‘상속’하면 인터페이스의 모든 함수들을 그를 상속하는 클래스 안에서 구현해야합니다. 구현이 클래스 안에 갖혀버림과 동시에 구현과 클래스 내부간의 강결합이 생깁니다.
반면 ‘구성’을 사용하면 인터페이스를 구현한 구현 클래스 단 하나로 어느곳에서든지 사용 가능합니다. 레고처럼 붙였다 떼었다 할 수 있어 쉽게 바꿀 수 있고, 구현 클래스 로직과 그걸 사용하는 클래스 간 결합이 풀리게 됩니다.



 * 쉬운 설명을 위해 CPU 는 Single Core 로 가정합니다.
* 쉬운 설명을 위해 CPU 는 Single Core 로 가정합니다.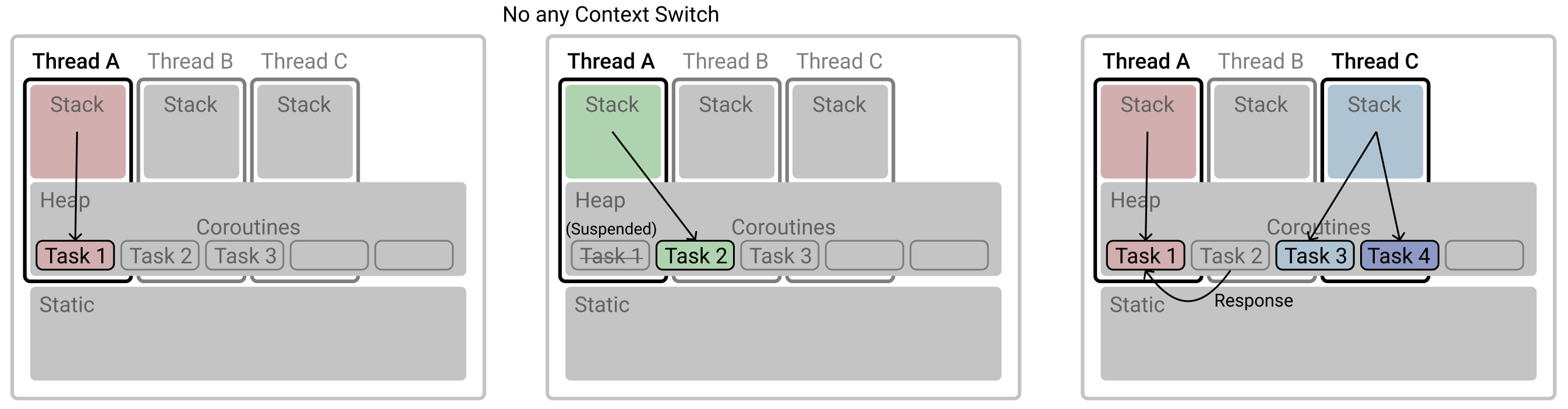 * 쉬운 설명을 위해 CPU 는 Single Core 로 가정합니다.
* 쉬운 설명을 위해 CPU 는 Single Core 로 가정합니다.











